A Análise de Correspondência (CA) é uma família de técnicas de análise exploratória de dados projetada para visualizar e analisar as associações entre variáveis categóricas. Neste capítulo, focaremos na sua forma mais fundamental: a Análise de Correspondência Simples (ACS), que analisa a relação entre duas variáveis categóricas a partir de uma tabela de contingência. A análise de três ou mais variáveis é tratada pela Análise de Correspondência Múltipla (ACM).
O principal objetivo da ACS é representar graficamente as categorias de ambas as variáveis (as linhas e colunas da tabela) como pontos em um espaço de baixa dimensão — geralmente um plano bidimensional — de forma que as relações entre elas possam ser facilmente interpretadas.
Assim como a Análise de Componentes Principais (ACP) busca resumir variáveis contínuas, a CA busca resumir variáveis categóricas. A ACP utiliza a variância como medida de dispersão e a distância Euclidiana para avaliar a proximidade entre as observações. A CA, por sua vez, utiliza uma medida análoga à variância, chamada inércia, e uma métrica de distância ponderada, a distância Qui-quadrado, para levar em conta a frequência relativa das categorias.
Geometricamente, a CA transforma os perfis de frequência das categorias em pontos em um mapa (chamado de biplot). Categorias com perfis de frequência semelhantes são posicionadas próximas umas das outras, enquanto categorias com perfis distintos são posicionadas distantes. Isso nos permite identificar padrões de associação, como quais categorias de uma variável tendem a ocorrer com mais frequência com quais categorias de outra variável.
11.1 A Tabela de Contingência
O ponto de partida da Análise de Correspondência é uma tabela de contingência (ou tabela de dupla entrada), que cruza duas variáveis categóricas.
Definição 11.1 Sejam \(X\) e \(Y\) duas variáveis categóricas com \(I\) e \(J\) categorias, respectivamente. Uma tabela de contingência \(\mathbf{N}\) de dimensão \(I \times J\) é uma matriz onde cada elemento \(n_{ij}\) representa a contagem (frequência absoluta) de observações que pertencem simultaneamente à \(i\)-ésima categoria de \(X\) e à \(j\)-ésima categoria de \(Y\).
A partir de \(\mathbf{N}\), definimos as seguintes quantidades:
Total Geral:\(n = \sum_{i=1}^{I} \sum_{j=1}^{J} n_{ij}\), o número total de observações.
Totais Marginais de Linha:\(n_{i.} = \sum_{j=1}^{J} n_{ij}\), o total de observações na \(i\)-ésima categoria de \(X\).
Totais Marginais de Coluna:\(n_{.j} = \sum_{i=1}^{I} n_{ij}\), o total de observações na \(j\)-ésima categoria de \(Y\).
Dividindo cada elemento da tabela pelo total geral \(n\), obtemos a matriz de correspondência\(\mathbf{P}\), onde cada elemento \(p_{ij} = n_{ij}/n\) representa a frequência relativa conjunta.
\[
\mathbf{P} = \frac{1}{n} \mathbf{N}
\]
As marginais de \(\mathbf{P}\) são os vetores de probabilidades marginais (termo que na Análise de Correspondência é frequentemente chamado de massa). O vetor com as probabilidades marginais das linhas, \(\mathbf{r}\), e o das colunas, \(\mathbf{c}\), são definidos como:
Probabilidade Marginal de Linha \(i\):\(p_{i.} = \sum_{j=1}^{J} p_{ij} = n_{i.}/n\). O vetor é \(\mathbf{r} = (p_{1.}, \dots, p_{I.})'\).
Probabilidade Marginal de Coluna \(j\):\(p_{.j} = \sum_{i=1}^{I} p_{ij} = n_{.j}/n\). O vetor é \(\mathbf{c} = (p_{.1}, \dots, p_{.J})'\).
As probabilidades marginais representam a importância relativa de cada categoria. Uma categoria com probabilidade marginal alta tem uma frequência maior na amostra e, portanto, terá mais peso na análise.
Exemplo 11.1 Suponha uma pesquisa sobre a preferência de plataforma de streaming (Netflix, Prime Video, HBO Max) por faixa etária (Jovem, Adulto). A tabela de contingência \(\mathbf{N}\) com as contagens poderia ser:
Faixa Etária
Netflix
Prime Video
HBO Max
Total (Marginal Linha)
Jovem
50
20
30
100 (0.50)
Adulto
40
40
20
100 (0.50)
Total (Marginal Coluna)
90 (0.45)
60 (0.30)
50 (0.25)
200 (1.00)
O total geral é \(n=200\). A matriz de correspondência \(\mathbf{P}\) seria:
Os vetores de probabilidades marginais são \(\mathbf{r} = (0.50, 0.50)'\) e \(\mathbf{c} = (0.45, 0.30, 0.25)'\).
11.2 Perfis e a Hipótese de Independência
A CA analisa a estrutura de associação entre as variáveis examinando como os perfis de frequência de uma variável mudam conforme as categorias da outra.
Definição 11.2
O perfil da linha \(i\) é um vetor de \(J\) elementos que mostra a distribuição de frequência da variável de coluna dentro da \(i\)-ésima categoria da variável de linha. Cada elemento é calculado como \(p_{ij} / p_{i.}\).
O perfil da coluna \(j\) é um vetor de \(I\) elementos que mostra a distribuição de frequência da variável de linha dentro da \(j\)-ésima categoria da variável de coluna. Cada elemento é calculado como \(p_{ij} / p_{.j}\).
O perfil médio das linhas é simplesmente o vetor de probabilidades marginais das colunas, \(\mathbf{c}\). Similarmente, o perfil médio das colunas é o vetor de probabilidades marginais das linhas, \(\mathbf{r}\).
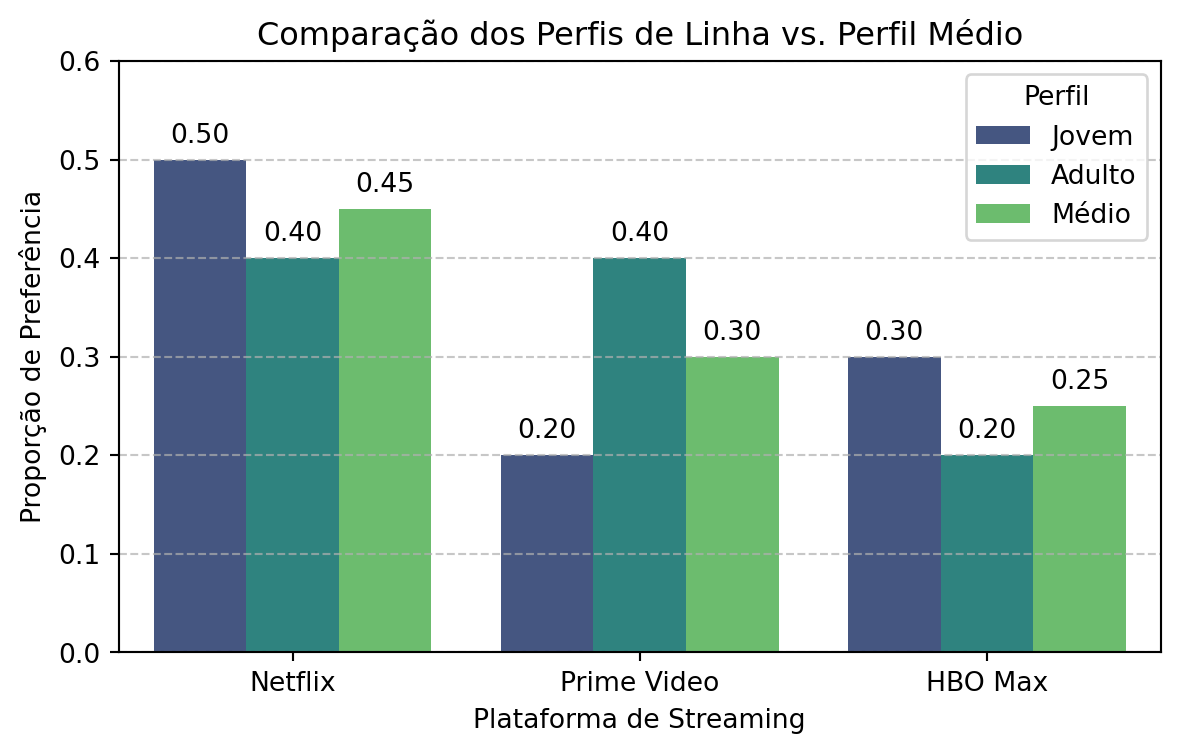
O perfil da linha “Jovem” (0.50, 0.20, 0.30) é diferente do perfil médio (0.45, 0.30, 0.25), indicando uma associação. Jovens têm uma preferência maior por Netflix (50% vs 45% na média) e menor por Prime Video (20% vs 30% na média).
Perfis de Coluna:
Faixa Etária
Netflix
Prime Video
HBO Max
Perfil Médio (r)
Jovem
0.56
0.33
0.60
0.50
Adulto
0.44
0.67
0.40
0.50
Total
1.00
1.00
1.00
1.00
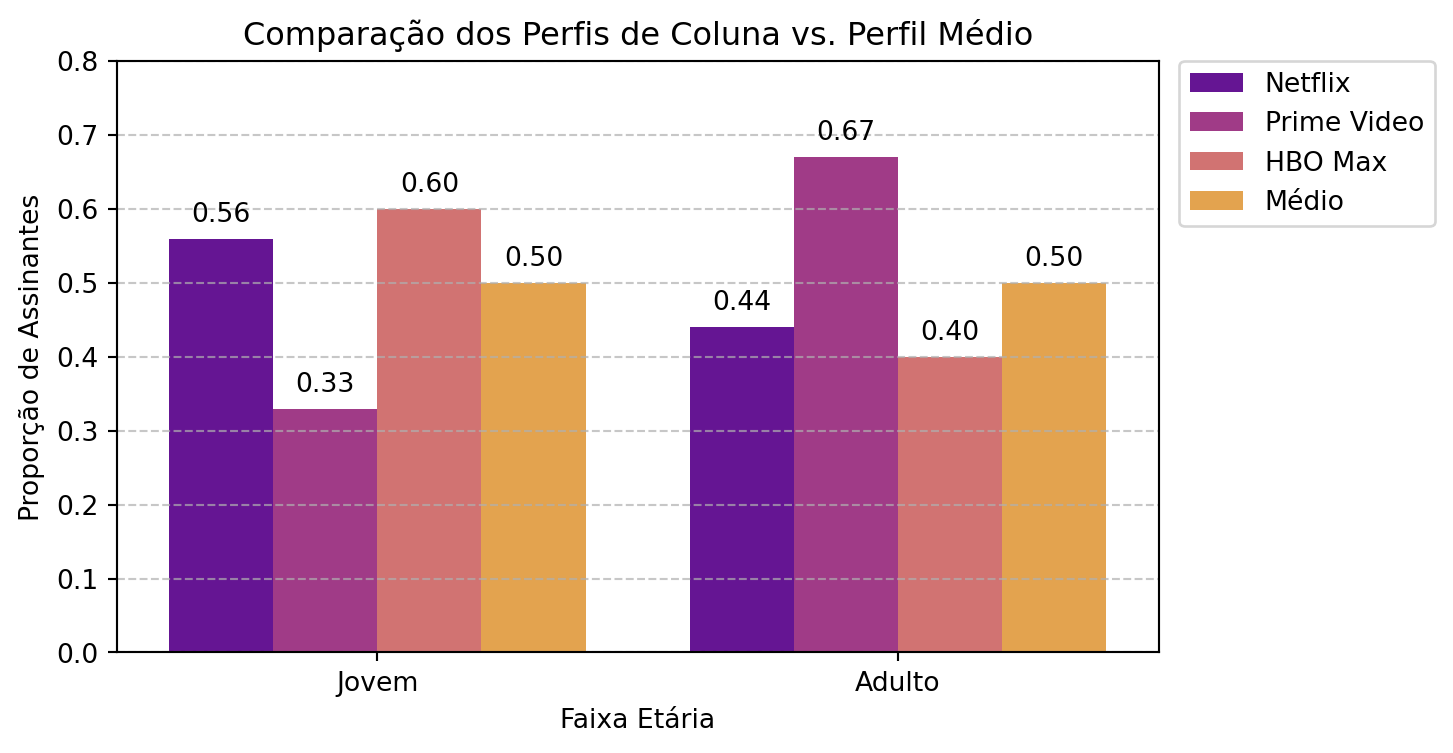
O perfil da coluna “Netflix” (0.56, 0.44) mostra que, entre os assinantes de Netflix, 56% são jovens, um valor ligeiramente acima da média de 50%.
O conceito central para a CA é a hipótese de independência. Sob independência, não há associação entre as variáveis, e o conhecimento de uma não altera a expectativa sobre a outra.
Definição 11.3 Duas variáveis categóricas são independentes se a frequência conjunta esperada for o produto de suas frequências marginais. Em termos da matriz de correspondência, a independência ocorre se:
\[
p_{ij} = p_{i.} p_{.j} \quad \forall i,j
\]
A matriz contendo estas probabilidades esperadas, denotada por \(\mathbf{E} = \mathbf{r}\mathbf{c}'\), representa a ausência total de associação. Sob independência, todos os perfis de linha são idênticos entre si e iguais ao perfil médio das linhas (\(\mathbf{c}\)). Da mesma forma, todos os perfis de coluna são idênticos e iguais ao perfil médio das colunas (\(\mathbf{r}\)).
A CA mede e visualiza o desvio da matriz observada \(\mathbf{P}\) em relação à matriz esperada \(\mathbf{E}\). Quanto mais o perfil de uma categoria específica se afasta do perfil médio, mais forte é a sua contribuição para a associação entre as variáveis.
Exemplo 11.3 Visualmente, podemos comparar os perfis de linha com o perfil médio. Se a hipótese de independência fosse verdadeira, os perfis de “Jovem” e “Adulto” seriam idênticos ao perfil “Médio”. O gráfico de barras abaixo ilustra como os perfis observados se desviam do perfil médio, evidenciando a associação entre faixa etária e preferência de streaming.
Código
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport numpy as np# Dados do Exemplo 11.2platforms = ['Netflix', 'Prime Video', 'HBO Max']dados = {'Jovem': [0.50, 0.20, 0.30],'Adulto': [0.40, 0.40, 0.20],'Médio': [0.45, 0.30, 0.25]}df = pd.DataFrame(dados, index=platforms).reset_index().melt(id_vars='index', var_name='Perfil', value_name='Proporção')df.rename(columns={'index': 'Plataforma'}, inplace=True)# Gráficofig, ax = plt.subplots(figsize=(7, 4))sns.barplot(x='Plataforma', y='Proporção', hue='Perfil', data=df, palette='viridis', ax=ax)ax.set_title('Comparação dos Perfis de Linha vs. Perfil Médio')ax.set_ylabel('Proporção de Preferência')ax.set_xlabel('Plataforma de Streaming')ax.set_ylim(0, 0.6)ax.grid(axis='y', linestyle='--', alpha=0.7)# Adiciona os valores nas barrasfor p in ax.patches: height = p.get_height()if height >0: ax.annotate(f'{p.get_height():.2f}', (p.get_x() + p.get_width() /2., p.get_height()), ha='center', va='center', xytext=(0, 9), textcoords='offset points')plt.show()
Figura 11.1: Comparação dos perfis de linha (Jovem, Adulto) com o perfil médio. A diferença na altura das barras para uma mesma plataforma indica uma associação entre as variáveis.
Da mesma forma, podemos visualizar a independência a partir dos perfis de coluna. O gráfico abaixo mostra que o perfil de preferência por faixa etária para os assinantes da “Prime Video” se destaca, com uma proporção muito maior de adultos (67%) em comparação com o perfil médio (50%).
Código
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport numpy as np# Dados para os perfis de colunaage_groups = ['Jovem', 'Adulto']dados_col = {'Netflix': [0.56, 0.44],'Prime Video': [0.33, 0.67],'HBO Max': [0.60, 0.40],'Médio': [0.50, 0.50]}df_cols = pd.DataFrame(dados_col, index=age_groups).reset_index().melt(id_vars='index', var_name='Perfil', value_name='Proporção')df_cols.rename(columns={'index': 'Faixa Etária'}, inplace=True)# Gráficofig, ax = plt.subplots(figsize=(7, 4))sns.barplot(x='Faixa Etária', y='Proporção', hue='Perfil', data=df_cols, palette='plasma', ax=ax)ax.set_title('Comparação dos Perfis de Coluna vs. Perfil Médio')ax.set_ylabel('Proporção de Assinantes')ax.set_xlabel('Faixa Etária')ax.set_ylim(0, 0.8)ax.grid(axis='y', linestyle='--', alpha=0.7)# Adiciona os valores nas barrasfor p in ax.patches: height = p.get_height()if height >0: ax.annotate(f'{p.get_height():.2f}', (p.get_x() + p.get_width() /2., p.get_height()), ha='center', va='center', xytext=(0, 9), textcoords='offset points')# Move a legenda para fora do gráficoax.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0)plt.show()
Figura 11.2: Comparação dos perfis de coluna (Netflix, Prime Video, HBO Max) com o perfil médio. As diferenças mostram como a distribuição de faixa etária varia entre os assinantes de cada plataforma.
11.3 A Distância Qui-Quadrado
Para medir a dissimilaridade entre os perfis, a distância Euclidiana padrão não é adequada. Ela sofre de dois problemas principais:
Sensibilidade à Frequência Marginal: A distância Euclidiana trata todas as categorias como igualmente importantes. No entanto, categorias com baixa frequência (e, portanto, baixa probabilidade marginal, ou massa) são mais suscetíveis a flutuações amostrais. Um pequeno desvio em uma categoria rara pode ser mais significativo do que um desvio semelhante em uma categoria muito comum.
Não considera o Perfil Médio: A distância não leva em conta a estrutura geral dos dados, representada pelos perfis médios.
Para resolver isso, a CA utiliza a distância Qui-quadrado (\(\chi^2\)).
Definição 11.4 A distância \(\chi^2\) é uma distância Euclidiana ponderada, projetada para resolver os problemas da distância Euclidiana padrão. A chave da sua formulação é a ponderação pelo inverso da probabilidade marginal do perfil médio (ou seja, \(1/p_{.j}\) para a comparação entre linhas e \(1/p_{i.}\) para a comparação entre colunas).
Essa ponderação tem um efeito importante:
Aumenta o peso de categorias com baixa frequência (baixa probabilidade marginal). Desvios nessas categorias são considerados mais significativos, pois são mais raros.
Diminui o peso de categorias com alta frequência (alta probabilidade marginal). Desvios nessas categorias são considerados menos informativos, pois pequenas flutuações são mais comuns.
Dessa forma, a distância foca na estrutura relativa dos perfis, e não apenas nas diferenças absolutas. As fórmulas são:
Distância entre dois perfis de linha (\(r\) e \(s\)):\[
d^2(r, s) = \sum_{j=1}^{J} \frac{1}{p_{.j}} \left( \frac{p_{rj}}{p_{r.}} - \frac{p_{sj}}{p_{s.}} \right)^2
\]
Distância entre dois perfis de coluna (\(c\) e \(d\)):\[
d^2(c, d) = \sum_{i=1}^{I} \frac{1}{p_{i.}} \left( \frac{p_{ic}}{p_{.c}} - \frac{p_{id}}{p_{.d}} \right)^2
\]
11.4 Inércia Total
A inércia total é a medida de dispersão central na Análise de Correspondência, análoga à variância total na ACP. Ela quantifica o desvio total dos perfis em relação à condição de independência.
Definição 11.5 A inércia total (\(\phi^2\)) de uma tabela de contingência é a soma ponderada das distâncias \(\chi^2\) de cada perfil de linha ao perfil médio das linhas (o vetor \(\mathbf{c}\), que representa as probabilidades marginais das colunas).
Devido à dualidade da análise, a inércia total também pode ser calculada de forma simétrica, como a soma ponderada das distâncias \(\chi^2\) de cada perfil de coluna ao perfil médio das colunas (o vetor \(\mathbf{r}\)):
Ambas as fórmulas para a inércia total são equivalentes e se simplificam para a mesma expressão final, que revela a conexão direta da inércia com a estatística Qui-quadrado de Pearson (\(\chi^2\)).
NotaDemonstração da Inércia Total
Para mostrar como a fórmula da inércia total se simplifica, vamos partir da definição baseada nos perfis de linha:
Esta é exatamente a fórmula da estatística Qui-quadrado de Pearson (\(\chi^2\)) dividida pelo total de observações (\(n\)), onde \(p_{ij}\) é a frequência observada e \(p_{i.}p_{.j}\) é a frequência esperada sob independência. O mesmo resultado é obtido ao partir da fórmula baseada nos perfis de coluna.
A inércia total é, portanto, a estatística \(\chi^2\) por observação, o que a torna uma medida de associação livre da influência do tamanho da amostra. Um valor de inércia igual a zero indica independência perfeita. Quanto maior a inércia, maior o grau de associação entre as variáveis. O objetivo da CA é decompor essa inércia total em dimensões ortogonais.
DicaRelação com a Estatística \(\chi^2\) de Pearson
A estatística \(\chi^2\) de Pearson é tradicionalmente calculada com as contagens (frequências absolutas), não com as probabilidades (frequências relativas). A fórmula é:
Onde \(\text{Observado}_{ij} = n_{ij}\) e a contagem esperada sob independência é \(\text{Esperado}_{ij} = \frac{n_{i.} \times n_{.j}}{n}\).
Para ver a relação entre \(\phi^2\) e \(\chi^2\), partimos da fórmula da inércia e substituímos as probabilidades pelas contagens. Lembrando que \(p_{ij} = n_{ij}/n\) e a contagem esperada sob independência é \(E_{ij} = n \cdot p_{i.}p_{.j}\):
Exemplo 11.4 Para a tabela do Exemplo 11.1, podemos calcular a inércia total usando a fórmula \(\phi^2 = \sum_{i,j} \frac{(p_{ij} - p_{i.}p_{.j})^2}{p_{i.}p_{.j}}\).
Um valor de inércia total de \(\phi^2 \approx 0.0489\) indica um desvio considerável da independência. A significância desta associação é avaliada pela estatística qui-quadrado de Pearson, dada por \(\chi^2 = n \times \phi^2\). Para nossa amostra de \(n=200\), temos \(\chi^2 \approx 200 \times 0.0489 = 9.78\).
Considerando \((2-1)(3-1) = 2\) graus de liberdade, o p-valor correspondente é de aproximadamente 0.0075. Como o p-valor é baixo, rejeita-se a hipótese de independência, o que confirma que a associação entre as variáveis é estatisticamente significativa e justifica a aplicação da Análise de Correspondência para explorar sua estrutura.
11.5 Análise de Correspondência Simples (ACS)
Sabemos que a inércia total (\(\phi^2\)) mede o quão longe nossa tabela está da independência. O próximo passo é entender a estrutura dessa associação. Assim como a Análise de Componentes Principais (Capítulo 7) decompõe a variância total para encontrar as direções de maior variação, a Análise de Correspondência decompõe a inércia total para encontrar os eixos (ou dimensões) que melhor explicam a associação entre as categorias.
Matematicamente, isso é resolvido encontrando a melhor aproximação de baixa dimensão para a nossa tabela de associação. A ferramenta para isso é a Decomposição em Valores Singulares (SVD), que é aplicada a uma matriz que representa os desvios da independência.
Primeiro, definimos as matrizes diagonais das probabilidades marginais (massas):
\(\mathbf{D}_r\): uma matriz diagonal \(I \times I\) com as probabilidades marginais das linhas (\(p_{i.}\)) na diagonal.
\(\mathbf{D}_c\): uma matriz diagonal \(J \times J\) com as probabilidades marginais das colunas (\(p_{.j}\)) na diagonal.
A matriz a ser decomposta, \(\mathbf{S}\), representa os resíduos da independência, padronizados pelas probabilidades marginais:
Onde \(\mathbf{E} = \mathbf{r}\mathbf{c}'\) é a matriz esperada sob independência.
NotaRelação entre S e a Inércia Total
Os elementos \(s_{ij}\) da matriz \(\mathbf{S}\) são os resíduos padronizados. Uma propriedade fundamental é que a soma dos quadrados de todos os elementos de S é igual à inércia total:
Lembrando a fórmula da inércia, \(\phi^2 = \sum_{i,j} \frac{(p_{ij} - p_{i.}p_{.j})^2}{p_{i.}p_{.j}}\), podemos ver que cada elemento de \(\mathbf{S}\) é \(s_{ij} = \frac{p_{ij} - p_{i.}p_{.j}}{\sqrt{p_{i.}p_{.j}}}\). Portanto, \(s_{ij}^2 = \frac{(p_{ij} - p_{i.}p_{.j})^2}{p_{i.}p_{.j}}\), e a soma de todos os \(s_{ij}^2\) resulta exatamente na inércia total.
Isso significa que a SVD de \(\mathbf{S}\) está, de fato, decompondo a inércia total da tabela.
\(\mathbf{U}\) é a matriz \(I \times K\) de vetores singulares à esquerda (ortogonais, \(\mathbf{U}'\mathbf{U} = \mathbf{I}\)).
\(\mathbf{V}\) é a matriz \(J \times K\) de vetores singulares à direita (ortogonais, \(\mathbf{V}'\mathbf{V} = \mathbf{I}\)).
\(\mathbf{\Lambda}\) é a matriz diagonal \(K \times K\) dos valores singulares \(\lambda_k\), em ordem decrescente. \(K = \min(I-1, J-1)\).
Os quadrados dos valores singulares, \(\lambda_k^2\), são chamados de inércias principais ou autovalores. Eles representam a porção da inércia total explicada por cada dimensão. A inércia total é a soma de todas as inércias principais: \(\phi^2 = \sum_k \lambda_k^2\).
Note que podemos rearranjar a Equação 11.1 para expressar a matriz de resíduos da independência, \(\mathbf{P} - \mathbf{E}\), em termos dos componentes da SVD. A SVD nos dá uma forma de decompor a inércia total em componentes ortogonais:
Essa decomposição é central para a CA. Ela nos diz que a matriz de resíduos (a “tabela de associação”) pode ser reconstruída como uma soma de tabelas de fatores. Como os valores singulares \(\lambda_k\) estão em ordem decrescente, os primeiros fatores (\(\mathbf{T}_1, \mathbf{T}_2, \dots\)) são os mais importantes, pois capturam a maior parte da inércia.
Isso nos permite criar uma aproximação de baixa dimensão para a nossa tabela. Para uma aproximação com \(M\) dimensões (onde \(M < K\)), simplesmente somamos os primeiros \(M\) fatores:
Por exemplo, a melhor aproximação de posto 2, que será usada para criar o biplot, é \(\mathbf{T}_1 + \mathbf{T}_2\). A qualidade da aproximação é medida pela proporção da inércia total capturada: \((\lambda_1^2 + \lambda_2^2) / \phi^2\). Mostramos isso na prática no exemplo da Capítulo 18.
As coordenadas principais, que são muito úteis para representações visuais, são calculadas a partir dos componentes da SVD:
Coordenadas Principais das Linhas:\(\mathbf{F} = \mathbf{D}_r^{-1/2} \mathbf{U} \mathbf{\Lambda}\).
Coordenadas Principais das Colunas:\(\mathbf{G} = \mathbf{D}_c^{-1/2} \mathbf{V} \mathbf{\Lambda}\).
NotaRelação entre as Coordenadas Principais e a Decomposição da Inércia
Podemos reescrever a matriz de fator \(\mathbf{T}_k\) usando as coordenadas da \(k\)-ésima dimensão (os vetores coluna \(\mathbf{f}_k\) e \(\mathbf{g}_k\)).
A partir das definições de \(\mathbf{F}\) e \(\mathbf{G}\), podemos expressar os vetores singulares \(\mathbf{u}_k\) e \(\mathbf{v}_k\) em função das coordenadas: \[
\mathbf{u}_k = \frac{1}{\lambda_k} \mathbf{D}_r^{1/2} \mathbf{f}_k \quad \text{e} \quad \mathbf{v}_k = \frac{1}{\lambda_k} \mathbf{D}_c^{1/2} \mathbf{g}_k
\] Substituindo-os na definição de \(\mathbf{T}_k = \lambda_k (\mathbf{D}_r^{1/2} \mathbf{u}_k) (\mathbf{D}_c^{1/2} \mathbf{v}_k)'\), a matriz de fator pode ser expressa como: \[
\mathbf{T}_k = \frac{1}{\lambda_k} (\mathbf{D}_r \mathbf{f}_k) (\mathbf{g}_k' \mathbf{D}_c)
\]
11.6 O Biplot e a Interpretação dos Resultados
A partir da decomposição da inércia, podemos criar uma representação visual aproximada, mas informativa, da associação, projetando as categorias em um espaço de poucas dimensões — geralmente duas. O resultado é o biplot, um gráfico que exibe as categorias de linha e de coluna simultaneamente, cujos eixos são as dimensões de maior inércia. Usando as coordenadas das duas primeiras dimensões, o biplot nos permite interpretar a estrutura subjacente dos dados.
A seguir, apresentamos notas práticas de como interpretar um biplot. Essa explicação é melhor entendida com um exemplo, por isso sugere-se a leitura do Capítulo 18 na sequência.
Como interpretar o biplot simétrico:
Distância entre pontos do mesmo conjunto: A distância Euclidiana entre dois pontos de linha (ou dois pontos de coluna) no biplot aproxima a distância \(\chi^2\) entre seus perfis.
Pontos próximos: Categorias com perfis semelhantes.
Pontos distantes: Categorias com perfis muito diferentes.
Posição relativa à origem: A distância de um ponto à origem (0,0) indica sua contribuição para a inércia total.
Pontos longe da origem: Categorias com perfis atípicos, que se afastam do perfil médio e contribuem significativamente para a associação.
Pontos perto da origem: Categorias com perfis próximos ao perfil médio, que desempenham um papel menor na estrutura de associação.
Relação entre pontos de conjuntos diferentes: A associação entre uma categoria de linha e uma categoria de coluna é interpretada pela sua proximidade e direção em relação à origem.
Categorias cujos pontos estão no mesmo lado (quadrante) do gráfico tendem a ter uma associação positiva (ocorrem juntas com mais frequência do que o esperado).
Categorias em lados opostos da origem tendem a ter uma associação negativa.
AvisoCuidado na Interpretação de Distâncias
Em um biplot simétrico (o tipo mais comum), a distância Euclidiana entre um ponto de linha e um ponto de coluna não tem uma interpretação direta e formal. Embora a proximidade visual possa sugerir uma forte associação — o que muitas vezes é verdade devido às relações de transição — a interpretação rigorosa deve se basear na posição relativa dos pontos em relação à origem e nas distâncias dentro de cada conjunto de categorias.
Além de inspecionar o biplot visualmente, é importante verificar a qualidade de sua representação no mapa. Para isso, observamos a proporção da inércia de cada ponto que é capturada pelas dimensões do biplot. A métrica mais adequada é o Cosseno ao Quadrado (\(cos^2\)). A fórmula para a linha \(i\) na dimensão \(k\) é: \[
cos^2_{ik} = \frac{F_{ik}^2}{\sum_{j=1}^K F_{ij}^2}
\]
Na prática, para que o biplot seja altamente informativo, precisamos queremos que as primeiras duas dimensões capturem uma grande fração da inércia. Em outras palavras, queremos \(cos^2_{i1} + cos^2_{i2}\) próximo de \(1\). É importante que isso seja verificado também para as colunas.
Uma vez confirmada a boa representação dos pontos, investigamos o significado dos eixos através da contribuição de cada ponto para a inércia de uma dimensão. A contribuição da linha \(i\) para a dimensão \(k\) é: \[
\text{Ctr}_{ik} = \frac{p_{i.} F_{ik}^2}{\lambda_k^2}
\] onde \(\lambda_k^2\) é a inércia do eixo. Um eixo é interpretado com base nas categorias que mais contribuem para ele.
11.7 Análise de Correspondência Múltipla (ACM)
Enquanto a Análise de Correspondência Simples (ACS) explora a associação entre duas variáveis, a Análise de Correspondência Múltipla (ACM) generaliza essa técnica para três ou mais variáveis categóricas. Embora seja frequentemente apresentada como uma única técnica, é muito útil pensar na ACM como dois métodos distintos, dependendo da matriz que serve de base para a análise:
ACM via Matriz Indicadora (\(\mathbf{Z}\)): Foca na relação entre indivíduos e variáveis.
ACM via Matriz (ou tabela) de Burt (\(\mathbf{B}\)): Foca exclusivamente na relação entre as variáveis.
Ambas as abordagens revelam a mesma estrutura de associação entre as categorias, mas diferem no objeto de análise e nas propriedades matemáticas (especialmente na inércia).
11.7.1 ACM via Matriz Indicadora (\(\mathbf{Z}\))
A abordagem mais completa da ACM utiliza a matriz indicadora (\(\mathbf{Z}\)), também conhecida como tabela de lógica.
Definição 11.6 Dado um conjunto de dados com \(N\) indivíduos e \(Q\) variáveis categóricas, a matriz indicadora\(\mathbf{Z}\) é uma matriz binária de dimensão \(N \times J\), onde \(J\) é o número total de categorias somadas de todas as variáveis.
As linhas representam os indivíduos.
As colunas representam as categorias de todas as variáveis.
O elemento \(z_{ij} = 1\) se o indivíduo \(i\) possui a categoria \(j\), e \(0\) caso contrário.
Ao aplicar o algoritmo da ACS diretamente sobre a matriz \(\mathbf{Z}\), tratamos os dados como uma grande tabela de contingência.
Principais Características:
Mapa Conjunto: Gera coordenadas tanto para as categorias quanto para os indivíduos.
Interpretação: Indivíduos próximos possuem perfis de resposta semelhantes. Um indivíduo é posicionado no centróide das categorias que ele selecionou.
Aplicação: Ideal para identificar perfis de indivíduos e para etapas subsequentes de análise, como agrupamento (clusterização).
11.7.2 ACM via Matriz de Burt (\(\mathbf{B}\))
Se o interesse é estritamente analisar como as variáveis se relacionam entre si, ignorando os indivíduos, utilizamos a Matriz de Burt (\(\mathbf{B}\)).
Definição 11.7 A Matriz de Burt é uma matriz simétrica \(J \times J\) que contém todas as tabelas de contingência cruzada entre os pares de variáveis. Ela é definida matematicamente como o produto da matriz indicadora por sua transposta:
\[
\mathbf{B} = \mathbf{Z}'\mathbf{Z}
\]
A aplicação da ACS sobre a Matriz de Burt foca puramente nas associações entre categorias.
Principais Características:
Mapa de Categorias: Gera coordenadas apenas para as categorias. A configuração geométrica é idêntica à obtida via \(\mathbf{Z}\).
Inércia Inflada: As inércias (autovalores) obtidas nesta análise são os quadrados das inércias obtidas na análise via matriz \(\mathbf{Z}\). Isso faz com que as dimensões pareçam explicar uma porcentagem muito maior da inércia total, o que pode ser enganoso.
Eficiência: Computacionalmente mais eficiente para grandes bases de dados onde \(N\) é muito grande, pois a matriz \(J \times J\) é geralmente menor que \(N \times J\).
Tabela 11.1: Comparação entre as abordagens de ACM via Matriz Indicadora e Matriz de Burt.
Característica
ACM via Matriz Indicadora (\(\mathbf{Z}\))
ACM via Matriz de Burt (\(\mathbf{B}\))
Matriz Base
Indivíduos \(\times\) Categorias (\(N \times J\))
Categorias \(\times\) Categorias (\(J \times J\))
Foco
Indivíduos e Categorias
Apenas Categorias
Inércia (\(\lambda\))
\(\lambda_k\) (menores)
\(\lambda_k^2\) (maiores, infladas)
Uso Principal
Análise detalhada, Clusterização
Análise estrutural das variáveis
11.7.3 A Particularidade da Inércia na ACM
A interpretação da inércia (variância explicada) requer cuidados especiais na ACM e se manifesta de forma diferente dependendo da matriz utilizada:
Na ACM via Matriz Indicadora (\(\mathbf{Z}\)): A inércia total é fixa e depende apenas do desenho da tabela (\(J\) categorias e \(Q\) variáveis): \[
\text{Inércia Total} = \frac{J - Q}{Q}
\] Devido a essa “inflação” da inércia total (que inclui muita variância de ruído), as porcentagens de inércia explicada por cada dimensão tendem a ser muito baixas (pessimistas), frequentemente abaixo de 20%, mesmo quando existem associações fortes.
Na ACM via Matriz de Burt (\(\mathbf{B}\)): Como os autovalores são os quadrados dos autovalores de \(\mathbf{Z}\) (\(\lambda_k^2\)), as porcentagens de explicação tornam-se matematicamente maiores e mais otimistas.
Portanto, a “particularidade” é relevante para ambos, mas com sinais opostos: \(\mathbf{Z}\) subestima a qualidade da representação visual, enquanto \(\mathbf{B}\) tende a superestimá-la.
Dica Prática:
Na ACM via matriz indicadora, não descarte dimensões apenas porque a % de inércia parece baixa.
Utilize o Critério de Benzécri: considere significativas as dimensões cujos autovalores superam a inércia média (\(1/Q\)).
Para reportar resultados, é comum calcular a Inércia Ajustada (frequentemente baseada nos autovalores da Matriz de Burt), que fornece uma estimativa mais realista da porcentagem de variação explicada.